
How We Can All Play the High-performance Game: From Laptops to Supercomputers
By Michael Bader, Hatem Ltaief, Lois Curfman McInnes, and Rio Yokota
The changing landscape of heterogeneous computing offers both unprecedented power and unprecedented complexity [7]. Given these challenges and opportunities, we discuss the necessity of international collaboration to develop open-source portable scientific software ecosystems, including the required functionality for advanced scientific computing. Such collaboration will enable all members of our community to fully exploit the computational power of hybrid machines—from laptops and desktops to clusters, supercomputers, and beyond—and advance scientific discovery.
In a recent letter to the editor in SIAM News, Nick Trefethen called attention to the divergence in computing performance on high-end supercomputers versus everyday laptop and desktop machines [12]. The article raises important considerations about the evolving landscape of computer architectures and implications for the future of computational science and high-performance computing (HPC). As current officers of the SIAM Activity Group on Supercomputing (SIAG/SC), we respond by considering heterogeneous computing architectures that are now readily available at all scales of computing, including on cell phones, laptops, desktops, and clusters. Heterogeneous designs—typically combinations of both central processing units (CPUs) and graphics processing units (GPUs) [11]—offer the potential of unprecedented computing power in a given computing environment (say, on a desktop); however, their unprecedented complexity means that most people cannot fully take advantage of that performance in their own local computing environments.
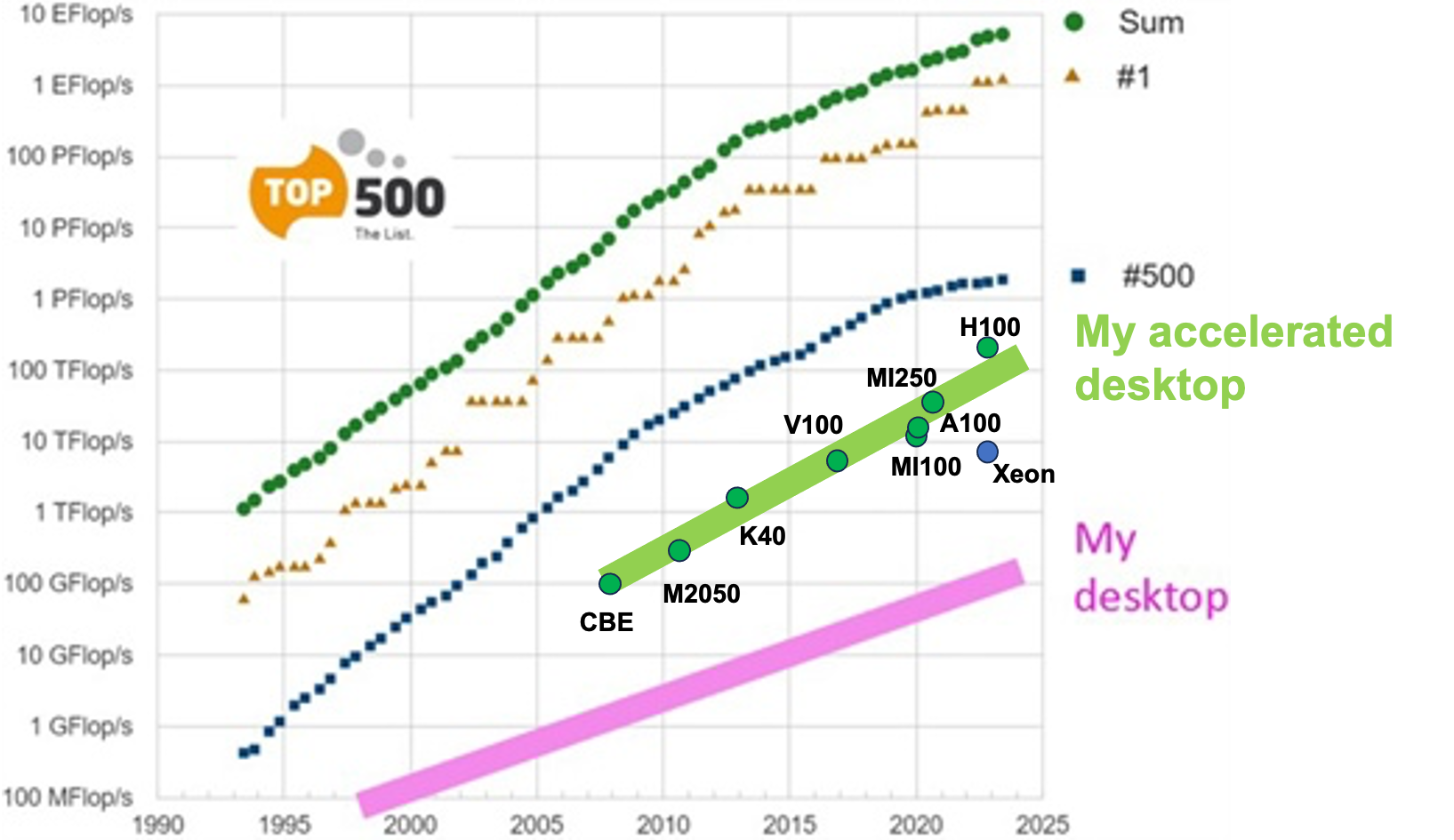
Trefethen points out that the trend of the computational power of the average desktop machine (as shown by the pink solid line in Figure 1) has advanced several orders of magnitude less than that of the largest machines on the TOP500 list. Indeed, most typical users of laptops and desktops readily write CPU-only code, achieving the level of performance in the figure.
Architectural Trends: Processors are Getting Faster, But Only with Parallel Codes
During the quest towards petascale and exascale computing, energy efficiency needs have forced architectures to extreme parallelism and complicated memory hierarchies. Even mainstream laptops and desktops are now parallel hybrid architectures, including both CPUs and GPUs. Figure 1 shows that when we fully leverage modern CPUs and GPUs, the growth of laptop and desktop computing power actually aligns with the growth of extreme-scale computing. However, the traditional approach to computing—which only employs the simple-to-use CPUs and omits the more difficult GPUs—leaves behind an enormous fraction of the machines’ untapped potential. A huge challenge therefore remains: Given the architectural complexity of these hybrid systems and the limited performance-portable open-source software that is tailored for these new architectures, how can we all play the HPC game?
Extracting the Full Potential of CPUs is Getting Harder
The high-end Intel Xeon Platinum 9282 has a theoretical peak of 9.3 TFlop/s (see Figure 1). One can achieve this performance only if the corresponding code can utilize the 56 cores and AVX-512 fused multiply-add instructions with a single instruction, multiple data vector width of eight doubles. If the code is not vectorized, users get 1/8 of the performance; if it is not multithreaded, they get another 1/56 of that. In practice, many issues—such as the algorithm’s arithmetic intensity and spatial/temporal locality of the implementation—further reduce the performance. Sole reliance on compilers to automatically solve all of these issues has been unsuccessful. Furthermore, porting code to GPUs is not the only challenge; both CPUs and GPUs may suffer from inadequate numerical algorithms and software ecosystems.
Deep Learning Inference Drives Hardware Architecture Design
Deep learning applications can tolerate extremely low levels of precision, and GPU vendors are taking advantage of this fact. While NVIDIA H100 GPUs achieve 134 TFlop/s in FP64 with Tensor Cores, they have a theoretical peak of about 2 PFlop/s for code that can fully utilize the FP16/BF16 sparse Tensor Cores, and close to 4 PFlop/s for code that can use FP8/INT8. Another bifurcation will evolve here if the scientific computing community cannot exploit this extra computing power. Techniques exist to recover double-precision accuracy via low-precision Tensor Cores at the matrix multiplication level [9, 10] and the solver level [1, 4]. But at the moment, such techniques are primarily exploited for certain dense/sparse linear algebra operations. In order for a wider range of scientific applications to benefit from these architectures, we need cross-cutting research in three key areas: (i) Theory and guidelines to profit from mixed precision while maintaining the fidelity of results [6], (ii) simulation software to improve performance portability, and (iii) robust and trustworthy software ecosystems to encapsulate functionality [8].
The Deep Learning Community Benefits from Algorithmic Uniformity
Scientific computing no longer drives supercomputing architectures. GPUs were originally developed to solve a few well-defined tasks in the realm of games and interactive graphics computing. Now they are serving the deep learning community by championing the forward and backward propagation of neural networks. This circumstance allows hardware manufacturers to aggressively optimize their architectures for a very narrow set of algorithms. Because of energy and cost constraints, processors can no longer simultaneously be general purpose and high performance. Neural network architectures have coevolved with GPUs, for which transformers (types of deep learning models) can extract a large portion of the Tensor Core’s theoretical peak Flop/s.
Architectural Features Drive Progress in High-performance Scientific Computing
The diversity of algorithms that are needed to address the broad range of scientific computing applications complicates the unified coevolution approach (see Figure 2). But will the scientific computing community therefore not be able to fully embrace the hardware evolution? We must redesign current algorithms, devise new algorithms, and refactor and redesign code to fully leverage the fast, low-precision hardware units and other features of heterogeneous architectures for scientific computing. A variety of groups throughout the international community have been pushing towards exascale computing with advances in algorithms and software [2, 3]. Because research advances that are driven by these extreme-scale systems tackle the on-node functionality that manifests across all scales of computing, this work also provides a foundation for performance improvement across desktops and clusters.

An Urgent Need for New Research and Scientific Software Ecosystems
The scientific computing community faces an urgent need for research on numerical algorithms to exploit the features of heterogeneous architectures, including mixed precision wherever applicable, complex memory hierarchies, and massive parallelism. Equally important is the development of open-source community software ecosystems that encapsulate this functionality for ready use by everyone. A combined approach of algorithmic advances and international collaboration on robust and trustworthy scientific software ecosystems will enable us to counter bifurcation and fully exploit the computing power of new heterogeneous architectures at all scales of computing.
Be there or be square. We welcome perspectives from the community. A great opportunity for discussion—hosted by the SIAM, ACM, and IEEE communities working groups on high-performance computing—is an upcoming Birds of a Feather session at SC23 (in Denver, Colorado on Wednesday, November 15, 12:15-1:15 pm MST): Meeting HPC Community Needs: How SIGHPC, TCPP, and SIAG-SC join efforts to engage communities and deliver services.
Also, we encourage everyone to attend the SIAM-PP24 Conference, to be held March 5-8, 2024 in Baltimore, Maryland, featuring an exciting program that highlights the latest advances in parallel processing for scientific computing.

Please join us to consider these topics … and many more in high-performance scientific computing.
References
[1] Abdelfattah, A., Anzt, H., Boman, E.G., Carson, E., Cojean, T., Dongarra, J., … Meier Yang, U. (2021). A survey of numerical linear algebra methods utilizing mixed-precision arithmetic. Int. J. High Perform. Comput. Appl., 35(4), 344-369, https://doi.org/10.1177/10943420211003313.
[2] Alam, S.R., McInnes, L.C., & Nakajima, K. (2022). IEEE special issue on “Innovative R&D Toward the Exascale Era.” IEEE Trans. Parallel Distrib. Syst., 33(4), 736-738, https://doi.org/10.1109/TPDS.2021.3109651.
[3] Anzt, H., Boman, E., Falgout, R., Ghysels, P., Heroux, M., Li, X., … Yang, U.M. (2020). Preparing sparse solvers for exascale computing. Phil. Trans. R. Soc. A: Math. Phys. Eng. Sci., 378(2166), 20190053, https://doi.org/10.1098/rsta.2019.0053.
[4] Haidar, A., Bayraktar, H., Tomov, S., Dongarra, J., & Higham, N.J. (2020). Mixed-precision iterative refinement using tensor cores on GPUs to accelerate solution of linear systems. Proc. R. Soc. A: Math. Phys. Eng. Sci., 476(2243), 20200110, https://doi.org/10.1098/rspa.2020.0110.
[5] Kothe, D., Lee, S., & Qualters, I. (2019). Exascale computing in the United States. IEEE Comput. Sci. Eng., 21(1), 17-29, https://doi.org/10.1109/MCSE.2018.2875366.
[6] Ltaief, H., Genton, M.G., Gratadour, D., Keyes, D.E., & Ravasi, M. (2022). Responsibly reckless matrix algorithms for HPC scientific applications. Comput. Sci. Eng., 24(4),12-22, https://doi.org/10.1109/MCSE.2022.3215477.
[7] Matsuoka, S., Domke, J., Wahib, M., Drozd, A., & Hoefler, T. (2023). Myths and legends in high-performance computing. Int. J. High Perform. Comput. Appl., 37(3-4), 245-259, https://doi.org/10.1177/10943420231166608.
[8] McInnes, L.C., Heroux, M.A., Draeger, E.W., Siegel, A., Coghlan, S., & Antypas, K. (2021). How community software ecosystems can unlock the potential of exascale computing. Nat. Comput. Sci., 1, 92-94, https://doi.org/10.1038/s43588-021-00033-y.
[9] Ootomo, H., Ozaki, K., & Yokota, R. (2023). DGEMM on integer matrix multiplication unit. Preprint, arXiv:2306.11975.
[10] Ootomo, H., & Yokota, R. (2022). Recovering single precision accuracy from tensor cores while surpassing the FP32 theoretical peak performance. Int. J. High Perform. Comput. Appl., 36(4), 475-491, https://doi.org/10.1177/10943420221090256.
[11] Rosso, M., & Myers, A. (2021). A gentle introduction to GPU programming. Better Scientific Software Blog. Retrieved from https://bssw.io/blog_posts/a-gentle-introduction-to-gpu-programming.
[12] Trefethen, N. (2023, September 1). A bifurcation in Moore’s law? SIAM News, 56(7), p. 2, https://sinews.siam.org/Details-Page/a-bifurcation-in-moores-law.






